1.LiveData
LiveData 的由来要追溯到 2017 年。那时,观察者模式有效简化了开发,但诸如 RxJava 一类的库有些太过复杂。为此,架构组件团队打造了 LiveData: 一个专用于 Android 的具备自主生命周期感知能力的可观察的数据存储器类。LiveData 被有意简化设计,这使得开发者很容易上手;而对于较为复杂的交互数据流场景,则建议您使用 RxJava或者Flow。
特点:
LiveData就是一个简单易用的,具备感知生命周期能力的可观察的,数据持有者,它使用起来非常简单,这是它的优点。
1、观察者的回调永远发生在主线程
2、仅持有单个且最新的数据,新数据会覆盖上一个
3、自动取消订阅,无需手动写
4、提供「可读可写」和「仅可读」两个版本收缩权限
缺点:
1.LiveData只能在主线程转换更新数据,postValue也是需要切换到到主线程的,当我们想要更新LiveData对象时,我们会经常更改线程(工作线程→主线程),如果在修改LiveData后又要切换回到工作线程那就更麻烦了,同时postValue可能会有丢数据的问题,在一段时间内发送数据的速度 > 接受数据的速度,LiveData 无法正确的处理这些请求。
2.LiveData结构简单就是有意被简化设计,LiveData的操作符也不够强大,面对比较复杂的交互数据流场景时,处理起来比较麻烦。

2.Flow
Flow 是 Kotlin 协程与响应式编程模型结合的产物,属于 Kotlin 协程的一部分,仅 Kotlin 使用。它与 RxJava 非常像,二者之间也有相互转换的 API,使用起来也较为方便,Flow是介于LiveData与RxJava之间的一个解决方案.
优点:
1.Flow 支持线程切换,LiveData不支持线程切换,所有数据转换都将在主线程上完成
2.Flow 入门的门槛较低,没有那么多傻傻分不清楚的操作符,而RxJava又有些过于麻烦了,同时需要自己处理生命周期,在生命周期结束时取消订阅
3.简单的数据转换与操作符,如 map,flowOn切换线程,transform 等等
4.冷数据流,不消费则不生产数据,这一点与LiveData不同:LiveData的发送端并不依赖于接收端。
5.属于kotlin协程的一部分,可以很好的与协程基础设施结合
2.1 SharedFlow
共享的Flow,可以实现一对多关系,SharedFlow是一种热流,有多个订阅者的需求就需要热流了
冷流:只有订阅者订阅时,才开始执行发射数据流的代码。并且冷流和订阅者只能是一对一的关系,当有多个不同的订阅者时,消息是重新完整发送的。也就是说对冷流而言,有多个订阅者的时候,他们各自的事件是独立的。
热流:无论有没有订阅者订阅,事件始终都会发生。当热流有多个订阅者时,热流与订阅者们的关系是一对多的关系,可以与多个订阅者共享信息。
构造函数:

1.replay表示当新的订阅者Collect时,发送几个已经发送过的数据给它,默认为0,即默认新订阅者不会获取以前的数据
2.extraBufferCapacity除了replay 的数量之外的缓冲区的大小,默认为0
3.onBufferOverflow表示缓存策略,即缓冲区满了之后Flow如何处理,默认为挂起
简单使用:
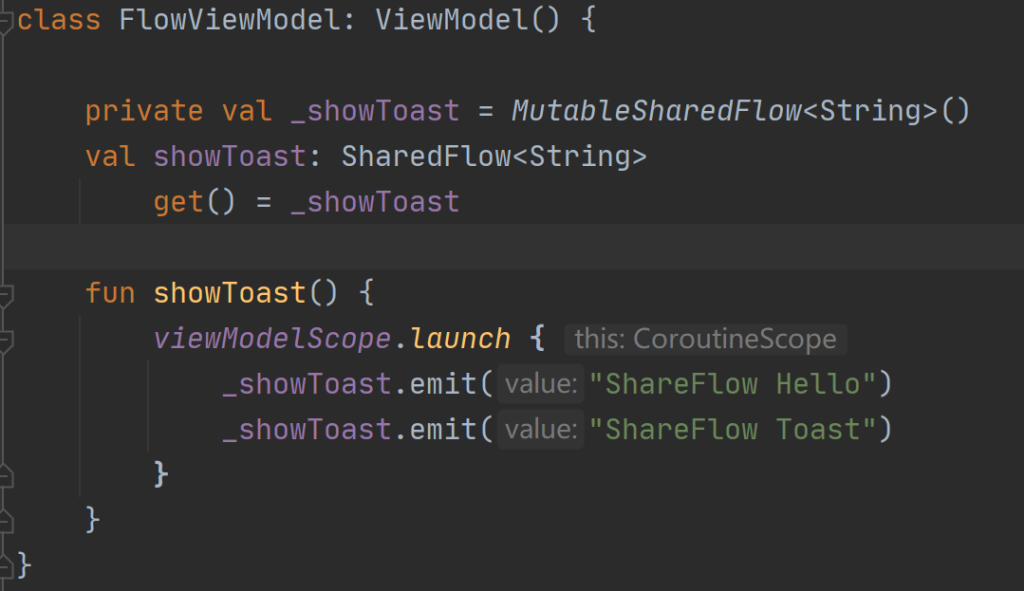
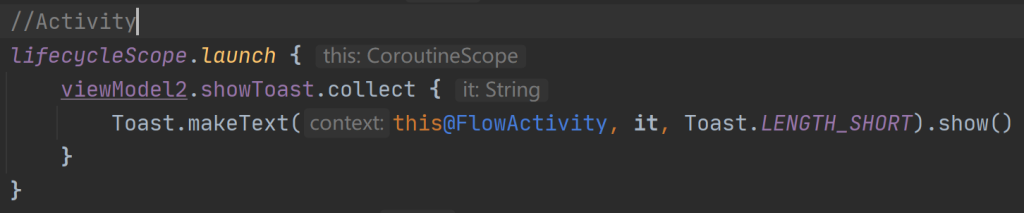
转换:
可使用shareIn扩展方法将Flow转化成SharedFlow
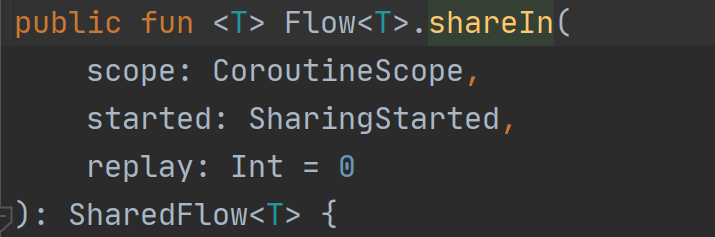
1.scope 共享开始时所在的协程作用域范围
2.started 控制共享的开始和结束的策略
2.1 Lazily: 当首个订阅者出现时开始,在scope指定的作用域被结束时终止。
2.2 Eagerly: 立即开始,而在scope指定的作用域被结束时终止。
2.3 WhileSubscribed:用来控制当最后一个订阅者消失时的行为,以及缓存的有效期,默认为当第一个订阅者出现的时候立即开始,当最后一个订阅者消失的时立即停止。

2.3.2 replayExpirationMillis表示数据重播的过时时间,如果用户离开应用太久,此时您不想让用户看到陈旧的数据,你可以用到这个参数
3.replay 状态流的重播个数
2.2 StateFlow
StateFlow 是 SharedFlow 的一个特殊变种,StateFlow 与 LiveData 是最接近的,推出就是为了替换LiveData
特性:
1.它始终是有值的,StateFlow需要一个初始值,而LiveData不需要。value空安全
2.它的值是唯一的。
3.它允许被多个观察者共用 (因此是共享的数据流)。
4.它永远只会把最新的值重现给订阅者,这与活跃观察者的数量是无关的。
构造函数:只需要传入一个默认值

1.StateFlow本质上是一个replay为1,并且没有缓冲区的SharedFlow,因此第一次订阅时会先获得默认值
2.StateFlow(防抖)仅在值已更新,并且值发生了变化时才会返回,即如果更新后的值没有变化,也没会回调Collect方法,这点与LiveData不同
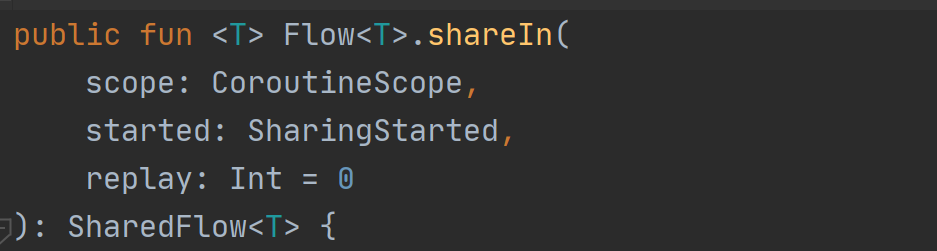
转换:
与SharedFlow类似,我们也可以用stateIn将普通流转化成StateFlow
观察StateFlow:
与LiveData类似,我们也需要在页面中观察StateFlow,LiveData 会与 Activity 绑定,当 View 进入 STOPED 状态时, LiveData.observer() 会自动取消注册,StateFlow和SharedFlow是热流,热流不会随着生命周期自动取消,也就是说页面消失后还会继续监听数据,或者下次进入时候会重复绑定,这样就会导致很多无法预料的错误。
观察StateFlow需要在协程中,一般我们会使用下面几种
1、lifecycleScope.launch : 立即启动协程,并且在本 Activity或Fragment 销毁时结束协程。
2、LaunchWhenStarted 和 LaunchWhenResumed,它会在lifecycleOwner进入X状态之前一直等待,又在离开X状态时挂起协程
StateFlow 或任意其他数据流收集数据的操作并不会停止,所以官方推荐repeatOnLifecycle来构建协程。
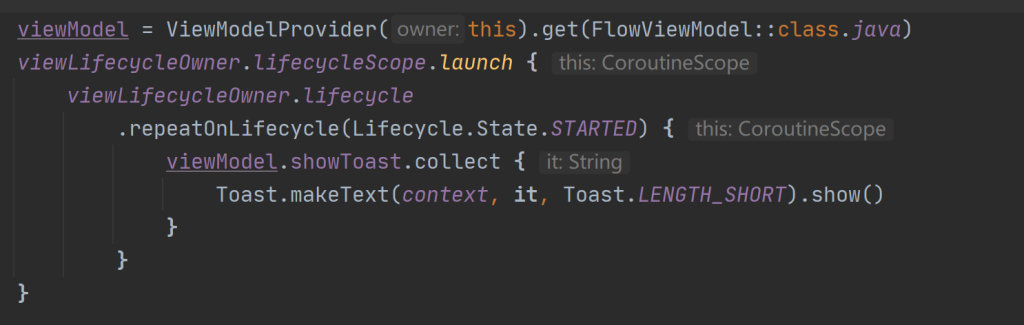
当这个Fragment处于STARTED状态时会开始收集流,并且在RESUMED状态时保持收集,最终在Fragment进入STOPPED状态时结束收集过程。
结合使用repeatOnLifecycle API和WhileSubscribed,可以帮助您的应用妥善利用设备资源的同时,发挥最佳性能
StateFlow与SharedFlow区别:
1、SharedFlow配置更为灵活,支持配置新的订阅者发送的缓冲区的数量replay,缓冲区大小、缓冲区溢出规则,StateFlow是SharedFlow的约束子类,replay固定为1,缓冲区大小默认为0,
2、StateFlow与LiveData类似,支持通过myFlow.value获取当前状态,如果有这个需求,必须使用StateFlow
3、SharedFlow支持发出和收集重复值,而StateFlow当value重复时,不会回调collect
4、对于新的订阅者,StateFlow只会重播当前最新值,SharedFlow可配置重播元素个数(默认为0,即不重播)
简单来说StateFlow是在SharedFlow上添加了一些默认的配置。
它忽略重复的值,并且是不可配置的。这会带来一些问题,比如当往List中添加元素并更新时,StateFlow会认为是重复的值并忽略
它需要一个初始值,并且在开始订阅时会回调初始值
它默认是粘性的,新用户订阅会获得当前的最新值,而且是不可配置的,而SharedFlow可以修改replay,如果不需要访问myFlow.value,并且享受SharedFlow的灵活性,可以选择考虑使用SharedFlow
总结:
LiveData简单往往意味着不够强大,而Flow强大又常常意味着复杂,两者往往不能兼得,软件开发过程中常常面临这种取舍。
LiveData的简单并不是它的缺点,而是它的特点。StateFlow与SharedFlow更加强大,但是学习成本也显著的更高.
我们应该根据自己的需求合理选择组件的使用
如果数据流比较简单,不需要进行线程切换与复杂的数据变换,LiveData已经足够了
如果数据流比较复杂,需要切换线程等操作,不需要发送重复值,需要获取myFlow.value,StateFlow对你来说是个好的选择
如果数据流比较复杂,同时不需要获取myFlow.value,需要配置新用户订阅重播无素的个数,或者需要发送重复的值,可以考虑使用SharedFlow
Kotlin数据流:
https://developer.android.google.cn/kotlin/flow?hl=zh-tw